| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MEEENATLLTEFVLTGFLYQPQWKIPLFLAFLVIYLITIMGNLGLIAVIWKDPHLHIPMYLLLGNLAFVDALLSSSVTLKMLINFLAKSKMISLSECKIQLFSFAISVTTECFLLATMAYDRYVAICKPLLYPAIMTNGLCIRLLILSYVGGLLHALIHEGFLFRLTFCNSNIIQHFYCDIIPLLKISYTDSSINFLMVFIFAGSIQVFTIGTVLISYIFVLYTILKKKSVKGMRKAFSTCGAHLLSVSLYYGPLAFMYMGSASPQADDQDMMESLFYTVIVPLLNPMIYSLRNKQVIASFTKMFKRNDV | |
| CCCCCCCCCCSSSSSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCHHHHHHHHHHHHCCCCCCCCHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCCCCHHHHHHHCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCHHHCHHHHHHHHHHHHHHHHSSSSCCCCCCCCCCCCSSSSSSCCHHHCCCCHHHCCCCHHHHHHHHHHHHHCCC | |
| 9998874220025865899925289999999999999999897999999518887674989976899985580013728898987248978848999999999999999999999999865146306210188016778999999999999999999999998452178999048440581888876257862657778889999999999999999999999980466757775431155889998999985452137378999878789889987221252133574405649899999999972669 |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MEEENATLLTEFVLTGFLYQPQWKIPLFLAFLVIYLITIMGNLGLIAVIWKDPHLHIPMYLLLGNLAFVDALLSSSVTLKMLINFLAKSKMISLSECKIQLFSFAISVTTECFLLATMAYDRYVAICKPLLYPAIMTNGLCIRLLILSYVGGLLHALIHEGFLFRLTFCNSNIIQHFYCDIIPLLKISYTDSSINFLMVFIFAGSIQVFTIGTVLISYIFVLYTILKKKSVKGMRKAFSTCGAHLLSVSLYYGPLAFMYMGSASPQADDQDMMESLFYTVIVPLLNPMIYSLRNKQVIASFTKMFKRNDV | |
| 8566230300100000004325010000130333133133233200300100130000001102000000010000000300020024422010300000010000000000100000001000000211202030033000000210101011002000000020201442201000001210020002233010000011013213313310330331001000103146323101000000210010232011000000224433344100002103200330030000213302400320164478 |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCCCCCSSSSSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCHHHHHHHHHHHHCCCCCCCCHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCCCCHHHHHHHCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCHHHCHHHHHHHHHHHHHHHHSSSSCCCCCCCCCCCCSSSSSSCCHHHCCCCHHHCCCCHHHHHHHHHHHHHCCC MEEENATLLTEFVLTGFLYQPQWKIPLFLAFLVIYLITIMGNLGLIAVIWKDPHLHIPMYLLLGNLAFVDALLSSSVTLKMLINFLAKSKMISLSECKIQLFSFAISVTTECFLLATMAYDRYVAICKPLLYPAIMTNGLCIRLLILSYVGGLLHALIHEGFLFRLTFCNSNIIQHFYCDIIPLLKISYTDSSINFLMVFIFAGSIQVFTIGTVLISYIFVLYTILKKKSVKGMRKAFSTCGAHLLSVSLYYGPLAFMYMGSASPQADDQDMMESLFYTVIVPLLNPMIYSLRNKQVIASFTKMFKRNDV | |||||||||||||||||||||||||
| 1 | 3emlA | 0.16 | 0.20 | 0.89 | 3.61 | Download | --------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS---GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAI-IVGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVL | |||||||||||||||||||
| 2 | 5tgzA | 0.21 | 0.23 | 0.88 | 2.01 | Download | -RGENFMDIECF----MVLNPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRK-DSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAV------------------------LPLLGWNCEKLQSVDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDQARMELAKTLVLILVVLIICWGPLLAIMVYDVFGKMNKLIKTVFSMLCLLNSTVNPIIYALRSKDLRHAFRSM------ | |||||||||||||||||||
| 3 | 4iaqA | 0.18 | 0.22 | 0.89 | 2.11 | Download | ------------YIYQDSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISL-------PPFFWRQAS--------------ECVVNTDHILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIIQKYAARERKATKTLGIILGAFIVCWLPFFIISLVMPIHLAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK-- | |||||||||||||||||||
| 4 | 4djh | 0.16 | 0.23 | 0.91 | 1.55 | Download | -------------------SPAIPVIITAVYSVVFVVGLVGNSLVMFVIIRYTKMKTATNIYIFNLALADALVTT-TMPFQSTVYLMNSWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPLKAKIINICIWLLSSSVGISAIVLGGTKVR---EDVDVIECSLQFPDD---DYSWWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLLRNLRRITRLVLVVVAVFVVCWTPIHIFILVEALGSAALSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCFP--- | |||||||||||||||||||
| 5 | 4yay | 0.17 | 0.22 | 0.91 | 1.26 | Download | KTTR-NAYIQKYLILNSSDCNYIFVMIPTLYSIIFVVGIFGNSLVVIVIYFYMKLKTVASVFLLNLALADLCFLLTLPLWAVYTAMEYRWPFGNYLCKIASASVSFNLYASVFLLTCLSIDRYLAIVHPMKSRLRRTMLVAKVTCIIIWLLAGLASLPAIIHR-NVFF------IITVCAFHYE--------TLPIGLGLTKNILGFLFPFLIILTSYTLIWKALK------KNDDIFKIIMAIVLFFFFSWIPHQIFTFLDLGIDIVDTAMPITICIAYFNNCLNPLFYGFLGKKFKRYFLQLL----- | |||||||||||||||||||
| 6 | 3emlA | 0.16 | 0.20 | 0.89 | 3.78 | Download | ---------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAIT--ISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCF-TFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVL | |||||||||||||||||||
| 7 | 4iaq | 0.22 | 0.23 | 0.85 | 1.72 | Download | --------------------LPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPPFF-WRQASECVVNT-----------------DHI---LYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIADARERKATKTLGIILGAFIVCWLPFFIISLVMPIH--L-AIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK-- | |||||||||||||||||||
| 8 | 4buoA | 0.17 | 0.18 | 0.86 | 2.70 | Download | ----NSDL-------DVNTDIYSKVLVTAIYLALFVVGTVGNSVTLFTLARKKSLQSTVDYYLGSLALSDLLILLLAMPVELYNFIWVHHPWAFAGCRGYYFLRDACTYATALNVVSLSVELYLAICHPFKAKTLMSRSRTKKFISAIWLASALLAIPMLFTMGLQNLSGDGTHPGGIVD---------TATLKVVIQVNTFMSFLFPMLVASILNTVIANKLTVMVHQPLRAVVIAFVVCWLPYHVRRLMFCYI-----------SDEQ-------WTYVSAAINPILYNLVSANFRQVFLSTL----- | |||||||||||||||||||
| 9 | 3emlA | 0.16 | 0.20 | 0.89 | 5.19 | Download | --------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS---GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAII-VGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVL | |||||||||||||||||||
| 10 | 2ydoA | 0.15 | 0.21 | 0.92 | 5.89 | Download | -----------------------SSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSAAAADILVGVLAIPFAIA--ISTGFCAACHGCLFIACFVLVLTASSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGQPKEGKAHSQGCGEGQVACLFEDVVPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLKQMESTLQKEVHAAKSLAIIVGLFALCWLTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVL | |||||||||||||||||||
| ||||||||||||||||||||||||||
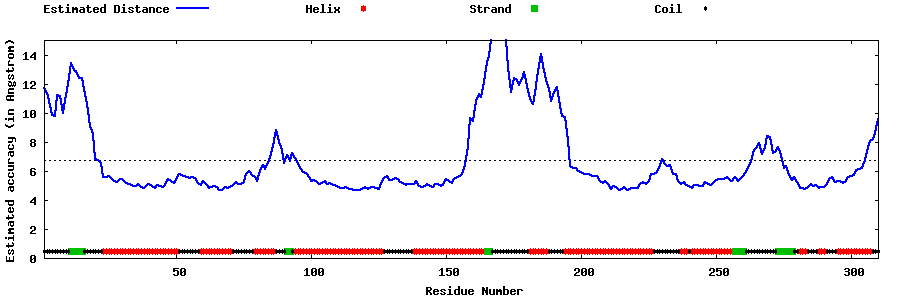
| Generated 3D models | Estimated local accuracy of models | ||
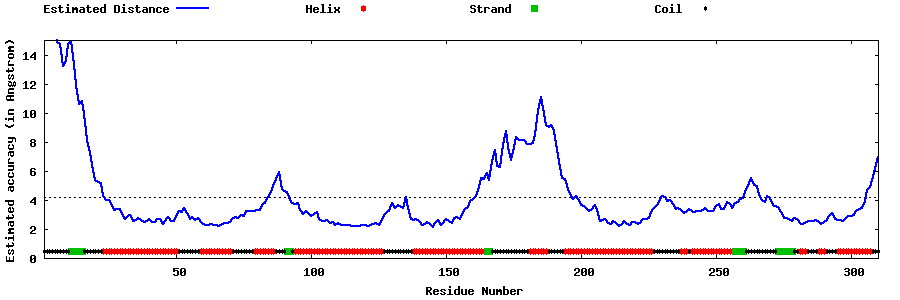 | |||
|
|
|||
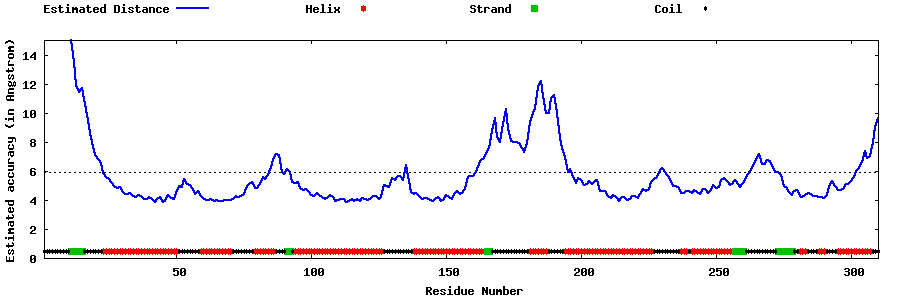 | |||
|
| |||
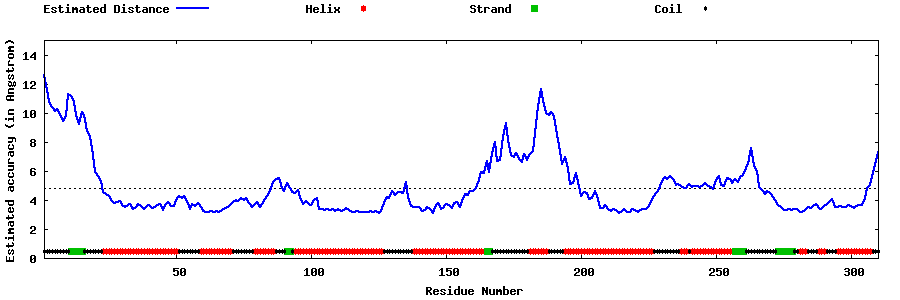 | |||
|
| |||
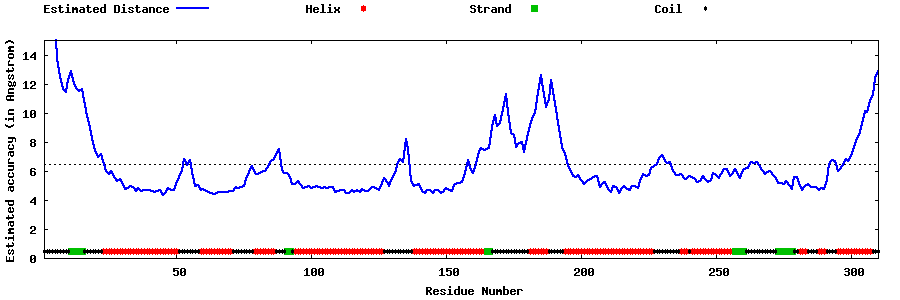 | |||
|
| |||
 | |||
|
| |||
