| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MTQINCTQVTEFILVGLTDRQELKMPLFVLFLSIYLFTVVGNLGLILLIRTDEKLNTPMYFFLSNLAFVDFCYSSVITPKMLGNFLYKQNSISFNACAAQLGCFLAFMTAECLLLASMAYDRYVAICNPLMYMVVMSPGICIQLVAAPHSYSILVALFHTILTFRLSYCHSNIVNHFYCDDMPLLRLTCSDTRFKQLWIFACAGIMFISSLLIVFVSYMFIISAILRMHSAEGRQKAFSTCGSHMLAVTIFYGTLIFMYLQPSSSHALDTDKMASVFYTVIIPMLNPLIYSLQNKEVKEALKKIIINKN | |
| CCCCCCCCCCSSSSSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHCCCCCCCCHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHSSSCCCCCCCCCCCCCHHHHHHHCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCHHHCHHHHHHHHHHHHHHHHSSSSCCCCCCCCCCCCSSSSSSCCHHHCCCCHHHCCCCHHHHHHHHHHHHHCC | |
| 999887422012586588982508999999999999999889799999850888777388886569988327101470889898714897884899999999999999999999999975413400622028802677899999999999999999999999845417899913844168088877704686376788899999999999999999999999998027775767543216588999799997444123747899987878988998721014124347450464989999999986069 |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MTQINCTQVTEFILVGLTDRQELKMPLFVLFLSIYLFTVVGNLGLILLIRTDEKLNTPMYFFLSNLAFVDFCYSSVITPKMLGNFLYKQNSISFNACAAQLGCFLAFMTAECLLLASMAYDRYVAICNPLMYMVVMSPGICIQLVAAPHSYSILVALFHTILTFRLSYCHSNIVNHFYCDDMPLLRLTCSDTRFKQLWIFACAGIMFISSLLIVFVSYMFIISAILRMHSAEGRQKAFSTCGSHMLAVTIFYGTLIFMYLQPSSSHALDTDKMASVFYTVIIPMLNPLIYSLQNKEVKEALKKIIINKN | |
| 856523030010000000432501010023033213313323310020020013000000100200001001000000020001001542201030001001000000110000000000000000020010003003300000012001100300201002003020043110100000010003000132312010002001311331331033033102100010302632310100011031001023201200000042431233420000210320023003000020330140033016448 |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCCCCCSSSSSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHCCCCCCCCHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHSSSCCCCCCCCCCCCCHHHHHHHCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCHHHCHHHHHHHHHHHHHHHHSSSSCCCCCCCCCCCCSSSSSSCCHHHCCCCHHHCCCCHHHHHHHHHHHHHCC MTQINCTQVTEFILVGLTDRQELKMPLFVLFLSIYLFTVVGNLGLILLIRTDEKLNTPMYFFLSNLAFVDFCYSSVITPKMLGNFLYKQNSISFNACAAQLGCFLAFMTAECLLLASMAYDRYVAICNPLMYMVVMSPGICIQLVAAPHSYSILVALFHTILTFRLSYCHSNIVNHFYCDDMPLLRLTCSDTRFKQLWIFACAGIMFISSLLIVFVSYMFIISAILRMHSAEGRQKAFSTCGSHMLAVTIFYGTLIFMYLQPSSSHALDTDKMASVFYTVIIPMLNPLIYSLQNKEVKEALKKIIINKN | |||||||||||||||||||||||||
| 1 | 3emlA | 0.19 | 0.21 | 0.89 | 3.62 | Download | --------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS---GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAI-IVGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHV | |||||||||||||||||||
| 2 | 5tgzA | 0.22 | 0.23 | 0.89 | 2.04 | Download | -RGENFMDIECF----MVLNPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRK-DSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVL------------------------PLLGWNCEKLQSVDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDQARMELAKTLVLILVVLIICWGPLLAIMVYDVFGKMNKLIKTVFAMLCLLNSTVNPIIYALRSKDLRHAFRSM----- | |||||||||||||||||||
| 3 | 4iaqA | 0.19 | 0.21 | 0.83 | 2.08 | Download | ------------YIYQDSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISILYTVYSTVGAF---------------------------------------YFPTLLLIALYGRIYVEARSRIIQKYAARERKATKTLGIILGAFIVCWLPFFIISLVMPIHLAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK- | |||||||||||||||||||
| 4 | 4djh | 0.15 | 0.23 | 0.91 | 1.54 | Download | -------------------SPAIPVIITAVYSVVFVVGLVGNSLVMFVIIRYTKMKTATNIYIFNLALADALVTT-TMPFQSTVYLMNSWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPLKAKIINICIWLLSSSVGISAIVLGGTKVRE---DVDVIECSLQFPDD---DYSWWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLLRNLRRITRLVLVVVAVFVVCWTPIHIFILVEALGSAALSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCFP-- | |||||||||||||||||||
| 5 | 4yay | 0.17 | 0.24 | 0.92 | 1.26 | Download | LKTTRNAYIQKYLILNSSDCPYIFVMIPTLYSIIFVVGIFGNSLVVIVIYFYMKLKTVASVFLLNLALADLCFLLTLPLWAVYTAMEYRWPFGNYLCKIASASVSFNLYASVFLLTCLSIDRYLAIVHPMKSRLRRTMLVAKVTCIIIWLLAGLASLPAIIHR-NVFF------IITVCAFHYE--------TLPIGLGLTKNILGFLFPFLIILTSYTLIWKALK------KNDDIFKIIMAIVLFFFFSWIPHQIFTFLDLGIDIVDTAMPITICIAYFNNCLNPLFYGFLGKKFKRYFLQLL---- | |||||||||||||||||||
| 6 | 3emlA | 0.18 | 0.21 | 0.89 | 3.77 | Download | ---------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAIT--ISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCF-TFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHV | |||||||||||||||||||
| 7 | 4iaq | 0.22 | 0.22 | 0.85 | 1.73 | Download | --------------------LPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPPFFW-RQASECVVN--------------------TDHILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIADARERKATKTLGIILGAFIVCWLPFFIISLVMPIH--LAI-FDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK- | |||||||||||||||||||
| 8 | 2z73A | 0.20 | 0.25 | 0.94 | 3.01 | Download | WY--NPSIVVHPHWREFDQVPAVYYSLGIFIGICGIIGCGGNGIVIYLFTKTKSLQTPANMFIINLAFSDFTFSLVNGPLMTISCFLKKWIFGFAACKVYGFIGGIFGFMSIMTMAMISIDRYNVIGRPMAASKKMSHRRAFIMIIFVWLWSVLWAIGPIFGWGAYTLEGV----------------LCSRDSTTRSNILCMFILGFFGPILIIFFCYFNIVMAQAGANAEMRLAKISIVIVSQFLLSWSPYAVVALLAQFGPLEWVTPYAAQLPVMFAKASAIHNPMIYSVSHPKFREAISQTFPWVL | |||||||||||||||||||
| 9 | 3emlA | 0.19 | 0.21 | 0.88 | 5.24 | Download | ----------------------ISSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS---GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAII-VGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHV | |||||||||||||||||||
| 10 | 2ydoA | 0.15 | 0.19 | 0.92 | 5.99 | Download | -----------------------SSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSAAAADILVGVLAIPFAIA--ISTGFCAACHGCLFIACFVLVLTASSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGQPKEGKAHSQGCGEGQVACLFEDVVPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLKQMESTLQKEVHAAKSLAIIVGLFALCWLTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHV | |||||||||||||||||||
| ||||||||||||||||||||||||||
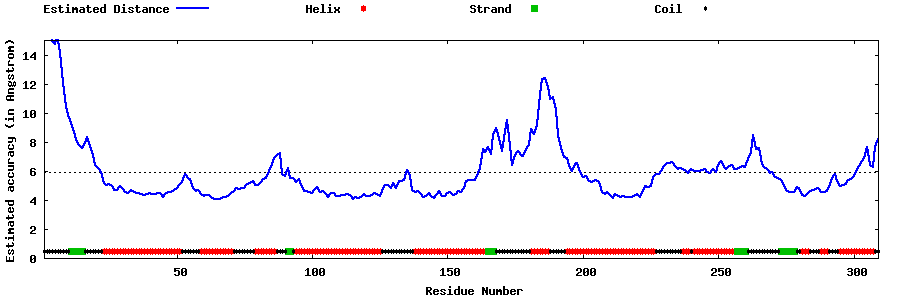
| Generated 3D models | Estimated local accuracy of models | ||
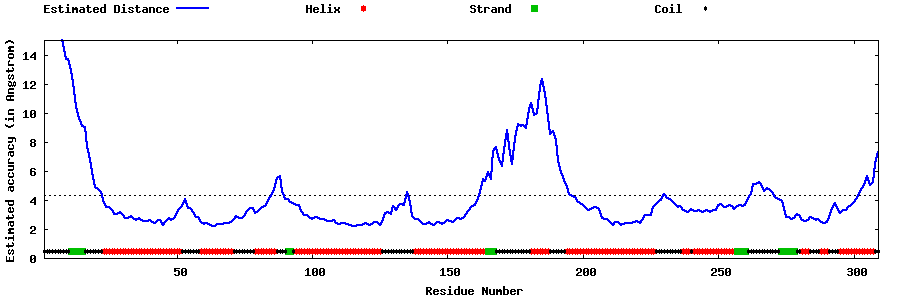 | |||
|
|
|||
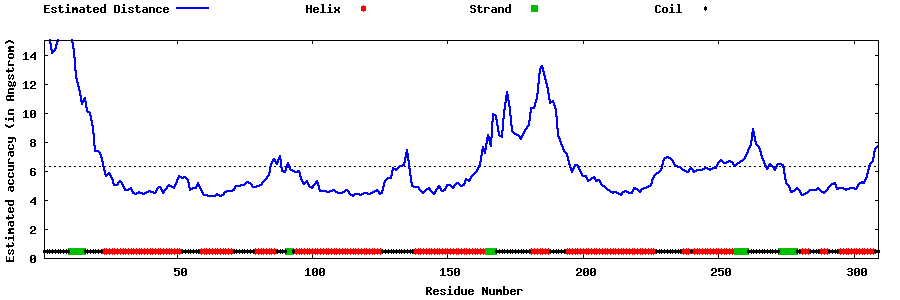 | |||
|
| |||
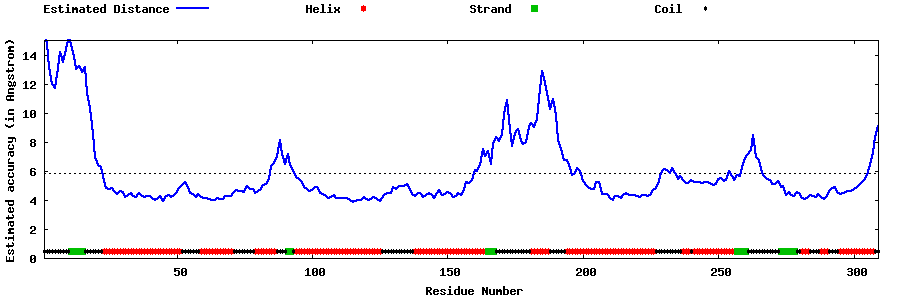 | |||
|
| |||
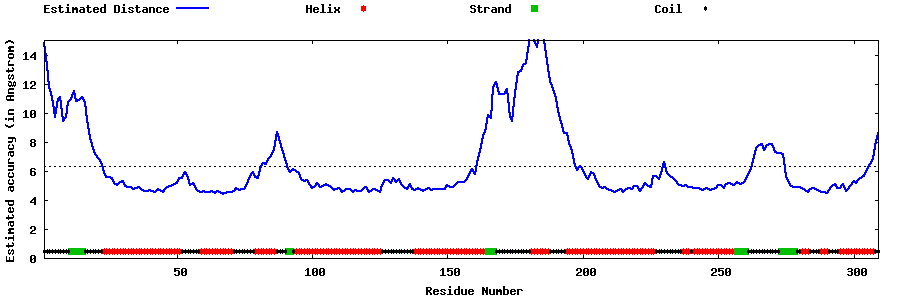 | |||
|
| |||
 | |||
|
| |||
