| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 | |
| | | | | | | | | | | | | | | | |
| MFGLFGLWRTFDSVVFYLTLIVGLGGPVGNGLVLWNLGFRIKKGPFSIYLLHLAAADFLFLSCRVGFSVAQAALGAQDTLYFVLTFLWFAVGLWLLAAFSVERCLSDLFPACYQGCRPRHASAVLCALVWTPTLPAVPLPANACGLLRNSACPLVCPRYHVASVTWFLVLARVAWTAGVVLFVWVTCCSTRPRPRLYGIVLGALLLLFFCGLPSVFYWSLQPLLNFLLPVFSPLATLLACVNSSSKPLIYSGLGRQPGKREPLRSVLRRALGEGAELGARGQSLPMGLL | |
| CCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHSSHHHHHHHHHHHHHHHHHHSSSSSSCCCCCSSHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCHHHHHHHHHHHCCCCCCCCCCCCCCCCCCC | |
| 9885258999999999999999999999899845422204788776999999999999999999999999996167654989999999999999999999987898870765166775210401117999999999865751578863699973103648899999999999999999999999998636788635687678889999987889999999999998899999999999999999999998700777455478999999864377878899999998889 |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 | |
| | | | | | | | | | | | | | | | |
| MFGLFGLWRTFDSVVFYLTLIVGLGGPVGNGLVLWNLGFRIKKGPFSIYLLHLAAADFLFLSCRVGFSVAQAALGAQDTLYFVLTFLWFAVGLWLLAAFSVERCLSDLFPACYQGCRPRHASAVLCALVWTPTLPAVPLPANACGLLRNSACPLVCPRYHVASVTWFLVLARVAWTAGVVLFVWVTCCSTRPRPRLYGIVLGALLLLFFCGLPSVFYWSLQPLLNFLLPVFSPLATLLACVNSSSKPLIYSGLGRQPGKREPLRSVLRRALGEGAELGARGQSLPMGLL | |
| 7242321220010211311320033133210200000002343101000000001000000200211101002333102001302332121113200000200000000001023213321000000100220020011210000023354120000111211103331312111210120001012224344410000000001101202322210000201332203101210100002000220200000044143233033003300423454667664344645 |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHSSHHHHHHHHHHHHHHHHHHSSSSSSCCCCCSSHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCHHHHHHHHHHHCCCCCCCCCCCCCCCCCCC MFGLFGLWRTFDSVVFYLTLIVGLGGPVGNGLVLWNLGFRIKKGPFSIYLLHLAAADFLFLSCRVGFSVAQAALGAQDTLYFVLTFLWFAVGLWLLAAFSVERCLSDLFPACYQGCRPRHASAVLCALVWTPTLPAVPLPANACGLLRNSACPLVCPRYHVASVTWFLVLARVAWTAGVVLFVWVTCCSTRPRPRLYGIVLGALLLLFFCGLPSVFYWSLQPLLNFLLPVFSPLATLLACVNSSSKPLIYSGLGRQPGKREPLRSVLRRALGEGAELGARGQSLPMGLL | |||||||||||||||||||||||||
| 1 | 5o9hA | 0.22 | 0.28 | 0.94 | 2.64 | Download | -----NTLRVPDILALVIFAVVFLVGVLGNALVVWVTAFEAKRTINAIWFLNLAVADFLACLALPALFTSIVQHHHWCSILPSLILLNMYASILLLATISADRFLLVFKPAWCQRFRGAGLAWILCAVAWGLALLLTIPSALYRVVREEYFPPKVLCGVRAVAIVRLVLGFLWPLLTLTICYTFILLRTETRSTKTLKVVVAVVASFFIFWLPYQVTGIMMSPTFLLLKKLDSLCVSFAYINCCINPIIYVVAGQGFQKS--LPELLREVLTEESVVR----------- | |||||||||||||||||||
| 2 | 4ntjA | 0.15 | 0.21 | 0.84 | 3.48 | Download | -------YKITQVLFPLLYTVLFFVGLITNGLAMRIFFQIRSKSNFIIFLKNTVISDLLMILTFPFKILSDALRTFVCQVTSVIFYFTMYISISFLGLITIDRYQKTTRPF---KTKNLLGAKILSVVIWAFMFLLSLPNMI--------LKSEFGLVWHEIVNYICQVIFWINFLIVIVCYTLITKELYRSRKKVNVKVFIIIAVFFICFVPFHFARIPYTLAENTLFYVKESTLWLTSLNACLNPFIYFFLCKSFRNSLI--------------------------- | |||||||||||||||||||
| 3 | 5o9hA | 0.23 | 0.28 | 0.94 | 3.71 | Download | -----NTLRVPDILALVIFAVVFLVGVLGNALVVWVTAFEAKRTINAIWFLNLAVADFLACLALPALFTSIVQHHHACSILPSLILLNMYASILLLATISADRFLLVFKPAWCQRFRGAGLAWILCAVAWGLALLLTIPSALYRVVREEYFPPKVLCGAIVRLVLGFLWPLLTLTICYTFILLRTWSARETRSTKTLKVVVAVVASFFIFWLPYQVTGIMMSPTFLLLKKLDSLCVSFAYINCCINPIIYVVAGQGFQKSL--PELLREVLTEESVVR----------- | |||||||||||||||||||
| 4 | 4djh | 0.16 | 0.19 | 0.90 | 1.52 | Download | -------SPAIPVIITAVYSVVFVVGLVGNSLVMFVIIRTKMKTATNIYIFNLALADALVTTTMPFQSTVMSFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPLKAKIINICIWLLSSSVGISAIVLGGTKVRDVDVIECSFMICVFIFAFVIPVLIIIVCYTLMILRLKSVRLRNLRRITRLVLVVVAVFVVCWTPIHIFILVEALGS-AALSSYYFCIALGYTNSSLNPILYAFLDEN--FKRCFRDFCFP-------------------- | |||||||||||||||||||
| 5 | 4xnv | 0.16 | 0.23 | 0.89 | 1.13 | Download | KCAL-TKTGFQFYYLPAVYILVFIIGFLGNSVAIWMFVFHMPWSGISVYMFNLALADFLYVLTLPALIFYYFNKTDWIFGDAMCKHVNLYGSILFLTCISAHRYSGVVYP-KSLGRLKKKNAICISVLVWLIVVVAISPILFYSGTGVRKNKTITCYDTFIYSMCTTVAMFCVPLVLILGCYGLIVRALIYKRRKSIYLVIIVLTVFAVSYIPFHVMKTMNLRARLRVYATYQVTRGLASLNSCVNPILYFLAGDTFRRR----------------------------- | |||||||||||||||||||
| 6 | 5o9hA | 0.22 | 0.28 | 0.93 | 2.96 | Download | -------LRVPDILALVIFAVVFLVGVLGNALVVWVTAFEAKRTINAIWFLNLAVADFLACLALPALFTSIVQHHHWCSILPSLILLNMYASILLLATISADRFLLVFKPAWCQRFRGAGLAWILCAVAWGLALLLTIPSALYRVVREEYFPPKVLRRERAVAIVRLVLGFLWPLLTLTICYTFILLRTWSRSTKTLKVVVAVVASFFIFWLPYQVTGIMMSFTFLLLKKLDSLCVSFAYINCCINPIIYVVAGQGFQKS--LPELLREVLTEESVVR----------- | |||||||||||||||||||
| 7 | 3uon | 0.13 | 0.19 | 0.88 | 1.70 | Download | -----------VVFIVLVAGSLSLVTIIGNILVMVSIKVRHLQTVNNYFLFSLACADLIIGVFSMNLYTLYTLGPVVCDLWLALDYVVSNASVMNLLIISFDRYFCVTKPLTYPVKRTTKMAGMMIAAAWVLSFILWAPAILFWQFIVRTVEDGECYIQFGTAIAAFYLPVIIMTVLYWHISRASKSRPPSREKKVTRTILAILLAFIITWAPYNVMVLINTFCACIPNTVWTIGYWLCYINSTINPACYALCNATFK--KTFKHLL---------------------- | |||||||||||||||||||
| 8 | 4mbsA | 0.18 | 0.22 | 0.90 | 2.98 | Download | V------KQIAARLLPPLYSLVFIFGFVGNMLVILILINYKRKSMTDIYLLNLAISDLFFLLTVPFWAHYAAAGNTMCQLLTGLYFIGFFSGIFFIILLTIDRYLAVVHAVFALKARTVTFGVVTSVITWVVAVFASLPNIIFYTCSSHFPYSQYQFWKNFQTLKIVILGLVLPLLVMVICYSGILKTLLREKHRDVRLIFTIMIVYFLFWAPYNIVLLLNTFSSNRLDQAMQVTETLGMTHCCINPIIYAFVGEEF--RNYLLVFFQ--------------------- | |||||||||||||||||||
| 9 | 4ntjA | 0.16 | 0.21 | 0.87 | 2.73 | Download | LCTRD--YKITQVLFPLLYTVLFFVGLITNGLAMRIFFQIRSKSNFIIFLKNTVISDLLMILTFPFKILSDALRTFVCQVTSVIFYFTMYISISFLGLITIDRYQKTTRPFKT---KNLLGAKILSVVIWAFMFLLSLPNMILKSEFG--------LVWHEIVNYICQVIFWINFLIVIVCYTLITKELYRSRKKVNVKVFIIIAVFFICFVPFHFARIPYCTAENTLFYVKESTLWLTSLNACLNPFIYFFLCKSF--RNSLISM----------------------- | |||||||||||||||||||
| 10 | 5o9hA | 0.22 | 0.28 | 0.94 | 3.86 | Download | -----NTLRVPDILALVIFAVVFLVGVLGNALVVWVTAFEAKRTINAIWFLNLAVADFLACLALPALFTSIVQHHHWCSILPSLILLNMYASILLLATISADRFLLVFKPAWCQRFRGAGLAWILCAVAWGLALLLTIPSALYRVVREEYFPPVLCRRERAVAIVRLVLGFLWPLLTLTICYTFILLRTWSRSTKTLKVVVAVVASFFIFWLPYQVTGIMMSPTFLLLKKLDSLCVSFAYINCCINPIIYVVAGQGFQK--SLPELLREVLTEESVVR----------- | |||||||||||||||||||
| ||||||||||||||||||||||||||
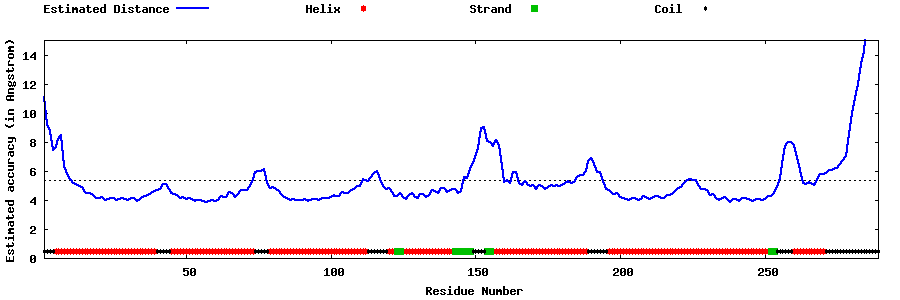
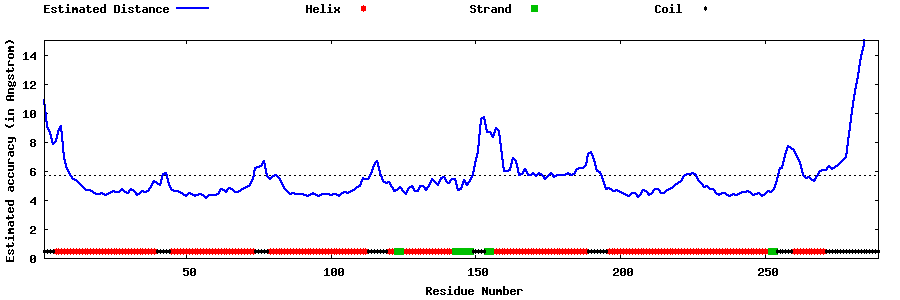
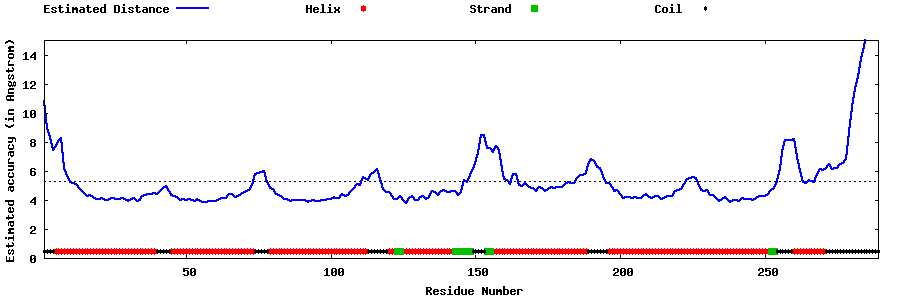
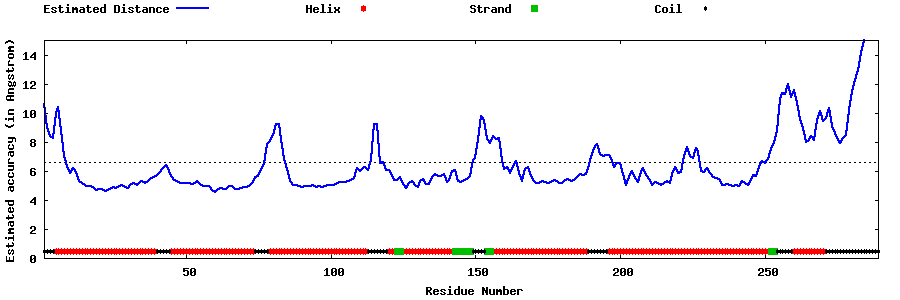
| Generated 3D models | Estimated local accuracy of models | ||
 | |||
|
|
|||
 | |||
|
| |||
 | |||
|
| |||
 | |||
|
| |||
 | |||
|
| |||
