| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MESENRTVIREFILLGLTQSQDIQLLVFVLVLIFYFIILPGNFLIIFTIKSDPGLTAPLYFFLGNLAFLDASYSFIVAPRMLVDFLSAKKIISYRGCITQLFFLHFLGGGEGLLLVVMAFDRYIAICRPLHYPTVMNPRTCYAMMLALWLGGFVHSIIQVVLILRLPFCGPNQLDNFFCDVPQVIKLACTDTFVVELLMVFNSGLMTLLCFLGLLASYAVILCRIRGSSSEAKNKAMSTCITHIIVIFFMFGPGIFIYTRPFRAFPADKVVSLFHTVIFPLLNPVIYTLRNQEVKASMKKVFNKHIA | |
| CCCCCCCCCSSSSSSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHSSSSSCCCCCCCCHHHHHHHHHHHHHHHHCCCHHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCHHHCCHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCSSCCCHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHCCSSSSSCCCCCCCCCCCSSHHHHHHHHHCCCCHHHCCCCHHHHHHHHHHHHHHCC | |
| 9987797223677836999841689999999999999998788725635417999997899988599987774411639999997359967848999999999999999999999999866088747331462306774899999999999999999999992338999988376874380888889403405556568777789999999999999999999951347403149998998899925476306314886889999853010466753454010374335629999999999852185 |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MESENRTVIREFILLGLTQSQDIQLLVFVLVLIFYFIILPGNFLIIFTIKSDPGLTAPLYFFLGNLAFLDASYSFIVAPRMLVDFLSAKKIISYRGCITQLFFLHFLGGGEGLLLVVMAFDRYIAICRPLHYPTVMNPRTCYAMMLALWLGGFVHSIIQVVLILRLPFCGPNQLDNFFCDVPQVIKLACTDTFVVELLMVFNSGLMTLLCFLGLLASYAVILCRIRGSSSEAKNKAMSTCITHIIVIFFMFGPGIFIYTRPFRAFPADKVVSLFHTVIFPLLNPVIYTLRNQEVKASMKKVFNKHIA | |
| 8566342200000000003244001000131333233233323300000200430300001002300120011000000200000025321000500000001103311310200020031000000221101000033100000120131023013001310230300001220001002210030000202301030023013102310331331121002001321461222001003002100302321010000003331330100003102310331130000204402300330144428 |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCCCCSSSSSSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHSSSSSCCCCCCCCHHHHHHHHHHHHHHHHCCCHHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCHHHCCHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCSSCCCHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHCCSSSSSCCCCCCCCCCCSSHHHHHHHHHCCCCHHHCCCCHHHHHHHHHHHHHHCC MESENRTVIREFILLGLTQSQDIQLLVFVLVLIFYFIILPGNFLIIFTIKSDPGLTAPLYFFLGNLAFLDASYSFIVAPRMLVDFLSAKKIISYRGCITQLFFLHFLGGGEGLLLVVMAFDRYIAICRPLHYPTVMNPRTCYAMMLALWLGGFVHSIIQVVLILRLPFCGPNQLDNFFCDVPQVIKLACTDTFVVELLMVFNSGLMTLLCFLGLLASYAVILCRIRGSSSEAKNKAMSTCITHIIVIFFMFGPGIFIYTRPFRAFPADKVVSLFHTVIFPLLNPVIYTLRNQEVKASMKKVFNKHIA | |||||||||||||||||||||||||
| 1 | 3emlA | 0.20 | 0.23 | 0.89 | 3.36 | Download | --------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS---GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVPMNYMVY-----------FNFFACVLVPLLLMLGVYLRIFLAARQLVHAAKSLAIIVGLFALCWLPLH-IINCFTFFCPDCAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVL | |||||||||||||||||||
| 2 | 5tgzA | 0.22 | 0.27 | 0.91 | 2.27 | Download | -RGENFMDIECF----MVLNPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRKD-SRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAV--------LPLLGWNCEKL---------QSVCSDIFHIDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDQARELAKTLVLILVVLIICWGPLLAIMVKMNKLIKTVFAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSM------ | |||||||||||||||||||
| 3 | 5tgzA | 0.18 | 0.27 | 0.89 | 2.07 | Download | ----------GGRGENFMDIPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFH-VFHRKDSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVLPLLCEKLQSVC-------------------SDIFPHIDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAARMDIELAKTLVLILVVLIICWGPLLAIMVGKMNLIKTVFAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSMF----- | |||||||||||||||||||
| 4 | 4djh | 0.16 | 0.23 | 0.91 | 1.54 | Download | -------------------SPAIPVIITAVYSVVFVVGLVGNSLVMFVIIRYTKMKTATNIYIFNLALADALVTT-TMPFQSTVYLMNSWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPLKAKIINICIWLLSSSVGISAIVLGGTKV---REDVDVIECSLQFPDD---DYSWWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLRNLRRITRLVLVVVAVFVVCWTPIHIFILVEALGSLSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCFP--- | |||||||||||||||||||
| 5 | 4yay | 0.17 | 0.21 | 0.92 | 1.23 | Download | KTTRN-AYIQKYLILNSSDCNYIFVMIPTLYSIIFVVGIFGNSLVVIVIYFYMKLKTVASVFLLNLALADLCFLLTLPLWAVYTAMEYRWPFGNYLCKIASASVSFNLYASVFLLTCLSIDRYLAIVHPMKSRLRRTMLVAKVTCIIIWLLAGLASLPAIIHRNVFF-------IITVCAFHYE--------TLPIGLGLTKNILGFLFPFLIILTSYTLIWKALK-----KNDDIFKIIMAIVLFFFFSWIPHQIFTFLDVLIVDTAMPITICIAYFNNCLNPLFYGFLGKKFKRYFLQLL----- | |||||||||||||||||||
| 6 | 5tgzA | 0.21 | 0.27 | 0.92 | 3.56 | Download | GRGENFMDIECFMVLN----PSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRK-DSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAV--------LPLLGWNCEK--------LQSVCSDIFPHIDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDQAIELAKTLVLILVVLIICWGPLLAIMVYDVFGIKTVFAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSMF----- | |||||||||||||||||||
| 7 | 4iaq | 0.20 | 0.24 | 0.86 | 1.74 | Download | --------------------LPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPPF-FWRQASECVVNT--------------------DHILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIAARERKATKTLGIILGAFIVCWLPFFIISLVMPIH-LAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK-- | |||||||||||||||||||
| 8 | 4buoA | 0.19 | 0.20 | 0.89 | 2.92 | Download | ----NSD-------LDVNTDIYSKVLVTAIYLALFVVGTVGNSVTLFTLARKKSLQSTVDYYLGSLALSDLLILLLAMPVELYNFIWVHHPWAFAGCRGYYFLRDACTYATALNVVSLSVELYLAICHPFKAKTLMSRSRTKKFISAIWLASALLAIPMLFTMGLQNLSGDGTHPGGLVCTPI------VDTATLKVVIQVNTFMSFLFPMLVASILNTVIANKLTVMVHQAVVIAFVVCWLPYHVRRLMFCYI-----------SDEQMLTNALVYVSAAINPILYNLVSANFRQVFLSTL----- | |||||||||||||||||||
| 9 | 5tgzA | 0.21 | 0.27 | 0.91 | 4.76 | Download | GRGENFMDIECFMVL----NPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFHVFH-RKDSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVLPLLG---------NCEK---------LQSVCSDIFHIDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAARMDIELAKTLVLILVVLIICWGPLLAIMVYDVFGKMN-FAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSMF----- | |||||||||||||||||||
| 10 | 2ydoA | 0.17 | 0.21 | 0.92 | 5.42 | Download | -----------------------SSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSAAAADILVGVLAIPFAIA--ISTGFCAACHGCLFIACFVLVLTASSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGQPKEGKAHSQGCGEGQVACLFEDVVPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRLKQMESTLQKEVHAAKSLAIIVGLFALCCFTFFCPDCSHAPLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVL | |||||||||||||||||||
| ||||||||||||||||||||||||||
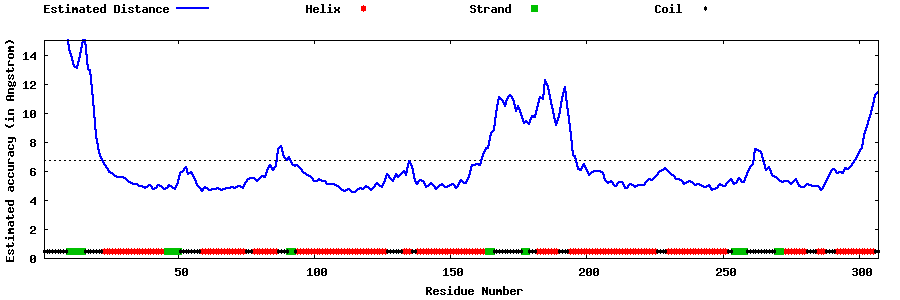
| Generated 3D models | Estimated local accuracy of models | ||
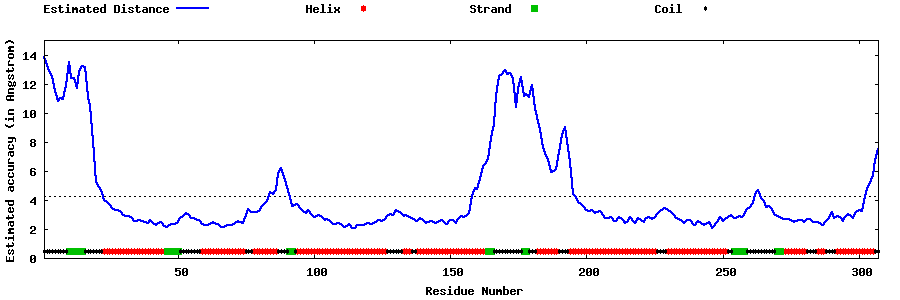 | |||
|
|
|||
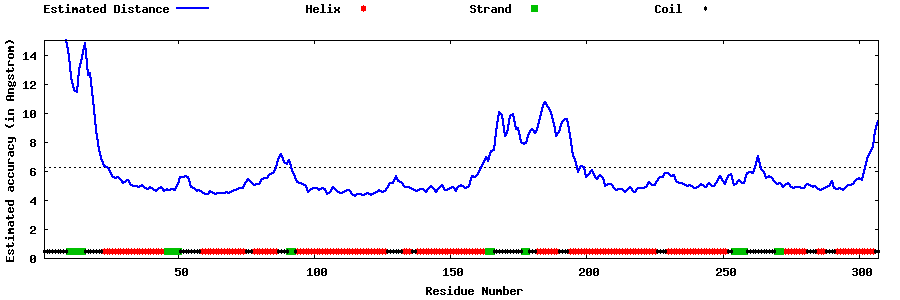 | |||
|
| |||
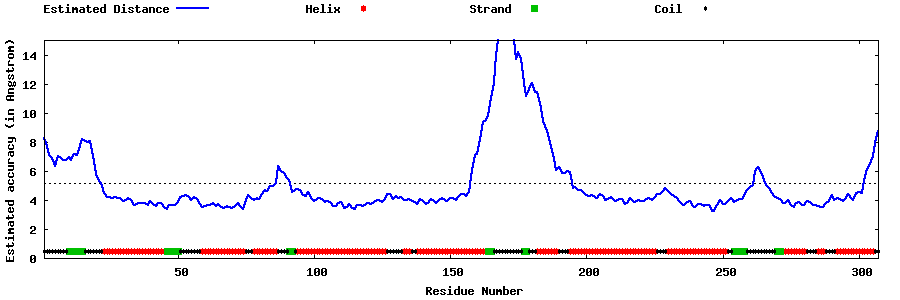 | |||
|
| |||
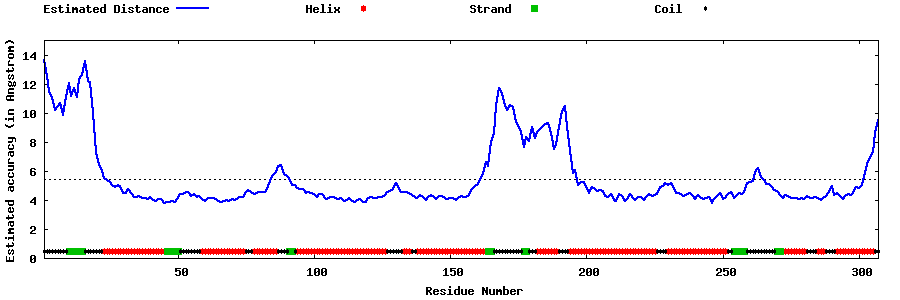 | |||
|
| |||
 | |||
|
| |||
