| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MNTTLFHPYSFLLLGIPGLESMHLWVGFPFFAVFLTAVLGNITILFVIQTDSSLHHPMFYFLAILSSIDPGLSTSTIPKMLGTFWFTLREISFEGCLTQMFFIHLCTGMESAVLVAMAYDCYVAICDPLCYTLVLTNKVVSVMALAIFLRPLVFVIPFVLFILRLPFCGHQIIPHTYGEHMGIARLSCASIRVNIIYGLCAISILVFDIIAIVISYVQILCAVFLLSSHDARLKAFSTCGSHVCVMLTFYMPAFFSFMTHRFGRNIPHFIHILLANFYVVIPPALNSVIYGVRTKQIRAQVLKMFFNK | |
| CCCCCCCCHHHSSSCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCCCHHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHCCCCCCCCSSSCCHHHHHHHHHHHHCCC | |
| 98988877223147998986788999999999999999999999998857887542289999999999999998439999999957998688878999999999999999999999981206620566546213888999999999999999999889999962899999944872211365688825683475899999999999989999999999999981788875888975414999999999999899996354126888837999999999738866468000065799999999984479 |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MNTTLFHPYSFLLLGIPGLESMHLWVGFPFFAVFLTAVLGNITILFVIQTDSSLHHPMFYFLAILSSIDPGLSTSTIPKMLGTFWFTLREISFEGCLTQMFFIHLCTGMESAVLVAMAYDCYVAICDPLCYTLVLTNKVVSVMALAIFLRPLVFVIPFVLFILRLPFCGHQIIPHTYGEHMGIARLSCASIRVNIIYGLCAISILVFDIIAIVISYVQILCAVFLLSSHDARLKAFSTCGSHVCVMLTFYMPAFFSFMTHRFGRNIPHFIHILLANFYVVIPPALNSVIYGVRTKQIRAQVLKMFFNK | |
| 72414230310200000121320200011022012203321210000020151001000200010020000002000020000000214403040000001200310330100011003000000021010000003410010000003213011202101021032045200000001021002000230300110002033123312310330112002000200246013201300100100010032313210100100330021000210221003013300300002034004100400267 |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCCCHHHSSSCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCCCHHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHCCCCCCCCSSSCCHHHHHHHHHHHHCCC MNTTLFHPYSFLLLGIPGLESMHLWVGFPFFAVFLTAVLGNITILFVIQTDSSLHHPMFYFLAILSSIDPGLSTSTIPKMLGTFWFTLREISFEGCLTQMFFIHLCTGMESAVLVAMAYDCYVAICDPLCYTLVLTNKVVSVMALAIFLRPLVFVIPFVLFILRLPFCGHQIIPHTYGEHMGIARLSCASIRVNIIYGLCAISILVFDIIAIVISYVQILCAVFLLSSHDARLKAFSTCGSHVCVMLTFYMPAFFSFMTHRFGRNIPHFIHILLANFYVVIPPALNSVIYGVRTKQIRAQVLKMFFNK | |||||||||||||||||||||||||
| 1 | 3emlA | 0.18 | 0.21 | 0.89 | 2.49 | Download | ------------------IM-GSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIST--GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDV----------VPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCFTFFC---PDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSH | |||||||||||||||||||
| 2 | 5tgzA | 0.20 | 0.21 | 0.87 | 2.11 | Download | --------------------SQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRRPSYHFIGSLAVADLLGSVIFVYSFIDF-HVFHRKDSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVLPLL-------GWNCEKLQSVC--------SDIFPHIDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDQARIELAKTLVLILVVLIICWGPLLAIMVYDVFGKMNKLIKTVFAFCSMLLLNSTVNPIIYALRSKDLRHAFRSMF--- | |||||||||||||||||||
| 3 | 5tjvA | 0.19 | 0.22 | 0.91 | 1.95 | Download | ------ENFMDIECFMVLNPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRRPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRK-DSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVLPLLCEKLQSVCSD-IFPHID-----------------ETYLMFWIGVTSVLLLFIVYAYMYILWKASFSDQARMDIRLAKTLVLILVVLIICWGPLLAIMVYDVFKMNKLIKTVFAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSMF--- | |||||||||||||||||||
| 4 | 3uon | 0.15 | 0.21 | 0.89 | 1.57 | Download | -------------------TFEVVFIVLVAGSLSLVTIIGNILVMVSIKVNRHLQTVNNYFLFSLACADLIIGVFSMNLYTLYTVIGYWPLGPVVCDLWLALDYVVSNASVMNLLIISFDRYFCVTKPLTYPVKRTTKMAGMMIAAAWVLSFILWAPAILFWQFIV--GVRTVEDGECYIQFF---------SNAAVTFGTIAAFYLPVIIMTVLYWHISRASKSRINISREKKVTRTILAILLAFIITWAPYNVMVLINTFCAPIPNTV-WTIGYWLCYINSTINPACYALCNATFKKTFKHLLM-- | |||||||||||||||||||
| 5 | 3uonA | 0.15 | 0.17 | 0.88 | 1.13 | Download | -------------------TFEVVFIVLVAGSLSLVTIIGNILVMVSIKVNRHLQTVNNYFLFSLACADLIIGVFSMNLYTLYTVIGYWPLGPVVCDLWLALDYVVSNASVMNLLIISFDRYFCVTKPLTYPVKRTTKMAGMMIAAAWVLSFILWAPAILFWQFI--VGVRTVEDGECYIQF---------FSNAAVTFGAIAAFYLPVIIMTVLYWHISRASKSR----REKKVTRTILAILLAFIITWAPYNVMVLINTFCAPCIPNTVWTIGYWLCYINSTINPACYALCNATFKKTFKHLLM-- | |||||||||||||||||||
| 6 | 3emlA | 0.18 | 0.21 | 0.89 | 2.72 | Download | --------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIST--GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCFTFFCPDC---SHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSH | |||||||||||||||||||
| 7 | 4iaq | 0.16 | 0.22 | 0.85 | 1.71 | Download | --------------------PWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPPFFW-RQASE----------CVVN----------TDHILYTVSTVGAFYFPTLLLIALYGRIYVEARSRIADARERKATKTLGIILGAFIVCWLPFFIISLVMPIH---L-AIFD-FFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRF- | |||||||||||||||||||
| 8 | 4buoA | 0.17 | 0.21 | 0.94 | 3.03 | Download | -NSDL---------DVNTDIYSKVLVTAIYLALFVVGTVGNSVTLFTLARKKSLQSTVDYYLGSLALSDLLILLLAMPVELYNFIWVHHPWAFAGCRGYYFLRDACTYATALNVVSLSVELYLAICHPFKAKTLMSRSRTKKFISAIWLASALLAIPMLFTMGLQNLSGDGTHPGGIVDTATLKVV----IQVNTFMSFLFPMLVASILNTVIANKLTVMVHQPGRVQALRRGVLVLRAVVIAFVVCWLPYHVRRLMFCYISDEQWTYHYFYMLTNALVYVSAAINPILYNLVSANFRQVFLSTL--- | |||||||||||||||||||
| 9 | 5tgzA | 0.20 | 0.21 | 0.91 | 3.19 | Download | ENFMDIEC--FMVLN----PSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRRPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRK-DSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVLPLLG-------NCEKLQSV-----------CSDIHIDKTYLMFWIGVVSVLLLFIVYAYMYILWKA-APDQARMDIELAKTLVLILVVLIICWGPLLAIMVYDVFGKMNKIKTVFAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSMF--- | |||||||||||||||||||
| 10 | 4gpoA | 0.16 | 0.21 | 0.90 | 4.78 | Download | ------------------LQQWEAGMSLLMALVVLLIVAGNVLVIAAIGSTQRLQTLTNLFITSLACADLVVGLLVVPFGATLVVRGTWLWGSFLCELWTSLDVLCVTASIETLCVIAIDRYLAITSPFRYQSLMTRARAKVIICTVWAISALVSFLPIMMHWWRDEDPQALKCYQDPG--------CCDFVTNRAYAIASSIIFYIPLLIMIFVALRVYREAKEQVMLMREHKALKTLGIIMGVFTLCWLPFFLVNIVNVFNRDLVPDWLFVAFNWLGYANSAMNPIIYC-RSPDFRKAFKRL---- | |||||||||||||||||||
| ||||||||||||||||||||||||||
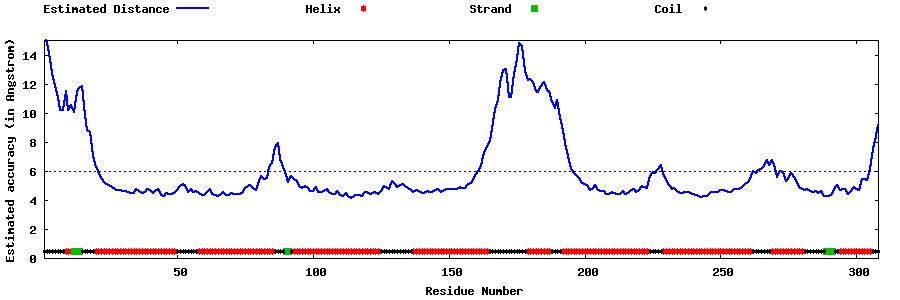
| Generated 3D models | Estimated local accuracy of models | ||
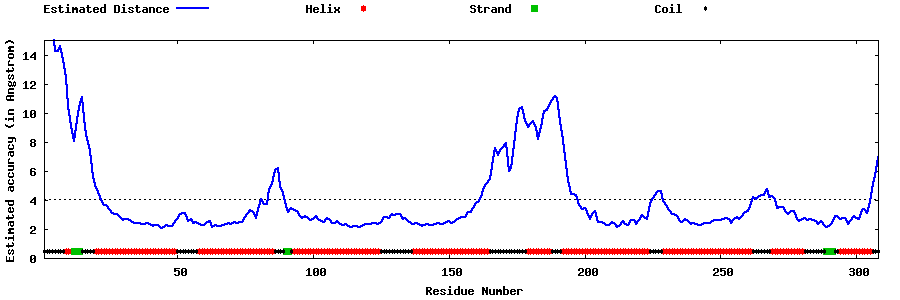 | |||
|
|
|||
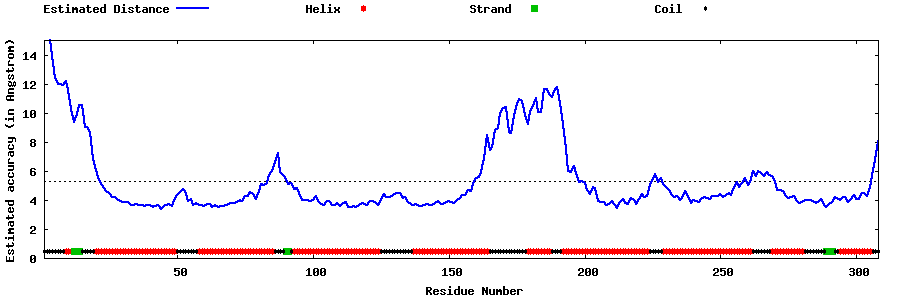 | |||
|
| |||
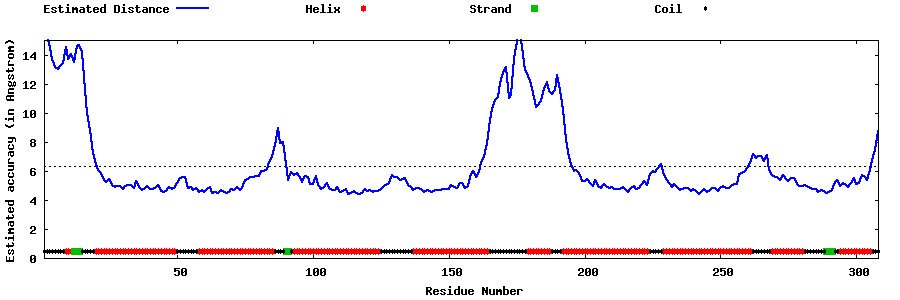 | |||
|
| |||
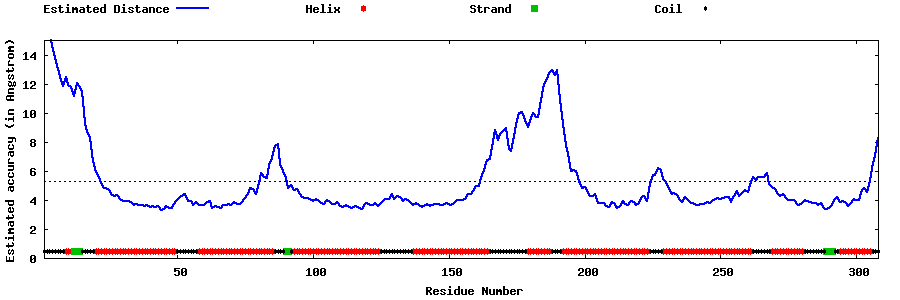 | |||
|
| |||
 | |||
|
| |||
