| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MESNQTWITEVILLGFQVDPALELFLFGFFLLFYSLTLMGNGIILGLIYLDSRLHTPMYVFLSHLAIVDMSYASSTVPKMLANLVMHKKVISFAPCILQTFLYLAFAITECLILVMMCYDRYVAICHPLQYTLIMNWRVCTVLASTCWIFSFLLALVHITLILRLPFCGPQKINHFFCQIMSVFKLACADTRLNQVVLFAGSAFILVGPLCLVLVSYLHILVAILRIQSGEGRRKAFSTCSSHLCVVGLFFGSAIVMYMAPKSSHSQERRKILSLFYSLFNPILNPLIYSLRNAEVKGALKRVLWKQRSM | |
| CCCCCCSSSSSSSSCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHHHHHCCCHHHHHHHHCCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCCCCCHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCHHCCHHHHHHHHHHHHHHHHSSSSCCCCCCCCCCCSSSSSHHHCHHHCCCCHHHCCCCHHHHHHHHHHHHHCCCC | |
| 9988643234457469998507999999999999999998899999997488756748999878999867555268899989856799658489999999999999999999999997640674065445782147759999999999999999999999990428999894489635848999885447419999999999999999899999999999999811866476662312658689979998610304781789999887780898505163231135633156499999999998635599 |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MESNQTWITEVILLGFQVDPALELFLFGFFLLFYSLTLMGNGIILGLIYLDSRLHTPMYVFLSHLAIVDMSYASSTVPKMLANLVMHKKVISFAPCILQTFLYLAFAITECLILVMMCYDRYVAICHPLQYTLIMNWRVCTVLASTCWIFSFLLALVHITLILRLPFCGPQKINHFFCQIMSVFKLACADTRLNQVVLFAGSAFILVGPLCLVLVSYLHILVAILRIQSGEGRRKAFSTCSSHLCVVGLFFGSAIVMYMAPKSSHSQERRKILSLFYSLFNPILNPLIYSLRNAEVKGALKRVLWKQRSM | |
| 8662303001000000033240111002302331331333332002001000300000001020000000101003102000101165320100002201100131033003000200200000002102000200330000001200220031031001100001003624010000032100200021031001102221333133122102301320020002031462231001000000000001220000000103163364341000021033313310300001042013002200344477 |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCSSSSSSSSCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHHHHHCCCHHHHHHHHCCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCCCCCHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCHHCCHHHHHHHHHHHHHHHHSSSSCCCCCCCCCCCSSSSSHHHCHHHCCCCHHHCCCCHHHHHHHHHHHHHCCCC MESNQTWITEVILLGFQVDPALELFLFGFFLLFYSLTLMGNGIILGLIYLDSRLHTPMYVFLSHLAIVDMSYASSTVPKMLANLVMHKKVISFAPCILQTFLYLAFAITECLILVMMCYDRYVAICHPLQYTLIMNWRVCTVLASTCWIFSFLLALVHITLILRLPFCGPQKINHFFCQIMSVFKLACADTRLNQVVLFAGSAFILVGPLCLVLVSYLHILVAILRIQSGEGRRKAFSTCSSHLCVVGLFFGSAIVMYMAPKSSHSQERRKILSLFYSLFNPILNPLIYSLRNAEVKGALKRVLWKQRSM | |||||||||||||||||||||||||
| 1 | 3emlA | 0.20 | 0.24 | 0.89 | 3.60 | Download | -------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITISTG--FCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINC-FTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSH-VL | |||||||||||||||||||
| 2 | 5tgzA | 0.20 | 0.21 | 0.90 | 2.17 | Download | -GENFMDIECF----MVLNPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRK-DSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVLPLL--------GWNCEKL---------QSVCSDIFPHDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHDQARMDIELAKTLVLILVVLIICWGPLLAIMVYDVFGKMNKLIKTVFSMLCLLNSTVNPIIYALRSKDLRHAFRSM------- | |||||||||||||||||||
| 3 | 4iaqA | 0.18 | 0.22 | 0.85 | 2.29 | Download | -----------YIYQDSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGR----WVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISL---------PPCVVNTDH-----------------ILYTVYSTVGAF---YFPTLLLIALYGRIYVEARSRIIQKMAARERKATKTLGIILGAFIVCWLPFFIISLVMPIHLAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK--- | |||||||||||||||||||
| 4 | 4djh | 0.15 | 0.23 | 0.91 | 1.54 | Download | ------------------SPAIPVIITAVYSVVFVVGLVGNSLVMFVIIRYTKMKTATNIYIFNLALADALVTT-TMPFQSTVYLMNSWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPLKAKIINICIWLLSSSVGISAIVLGGTKVR---EDVDVIECSLQFPDD---DYSWWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLDRNLRRITRLVLVVVAVFVVCWTPIHIFILVEALGSAALSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCFP---- | |||||||||||||||||||
| 5 | 4yay | 0.17 | 0.23 | 0.91 | 1.25 | Download | KTTRNAYIQKYLILNSSDCNYIFVMIPTLYSIIFVVGIFGNSLVVIVIYFYMKLKTVASVFLLNLALADLCFLLTLPLWAVYTAMEYRWPFGNYLCKIASASVSFNLYASVFLLTCLSIDRYLAIVHPMKSRLRRTMLVAKVTCIIIWLLAGLASLPAIIHRNVFF-------IITVCAFHYE--------TLPIGLGLTKNILGFLFPFLIILTSYTLIWKALK------KNDDIFKIIMAIVLFFFFSWIPHQIFTFLQLGIDIVDTAMPITICIAYFNNCLNPLFYGFLGKKFKRYFLQLL------ | |||||||||||||||||||
| 6 | 3emlA | 0.20 | 0.24 | 0.89 | 3.90 | Download | --------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAIT--ISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCF-TFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLR | |||||||||||||||||||
| 7 | 4iaq | 0.18 | 0.23 | 0.84 | 1.73 | Download | --------------------PWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPPF-FWRQASECVVN----------T----------DHILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIADARERKATKTL---GIILGAFIVCWLPFFIVMPIH--L-AIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK--- | |||||||||||||||||||
| 8 | 4ea3A | 0.20 | 0.22 | 0.81 | 3.12 | Download | ------------------PLGLKVTIVGLYLAVCVGGLLGNCLVMYVILRHTKMKTATNIYIFNLALADTLVLL-TLPFQGTDILLGFWPFGNALCKTVIAIDYYNMFTSTFTLTAMSVDRYVAICHPTSSKAQAVNVAIWALASVVGVPVAIMGSAQV---------EDEEIDYWGPVFAICIFLFSF-----------------IVPVLVISVCYSLMIRRLRGVRLLSGSVAVFVGCWTPVQVFVLAQGLG-----VQPSSETAVAILRFCTALGYVNSCLNPILYAFLDENFKACFR--------- | |||||||||||||||||||
| 9 | 3emlA | 0.19 | 0.24 | 0.89 | 4.87 | Download | -------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS--TGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAI-IVGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLR | |||||||||||||||||||
| 10 | 2ydoA | 0.20 | 0.24 | 0.92 | 5.69 | Download | ----------------------SSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSAAAADILVGVLAIPFAIA--ISTGFCAACHGCLFIACFVLVLTASSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGQPKEGKAHSQGCGEGQVACLFEDVVPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLKQMESTLQKEVHAAKSLAIIVGLFALCWLTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLR | |||||||||||||||||||
| ||||||||||||||||||||||||||
| Generated 3D models | Estimated local accuracy of models | ||
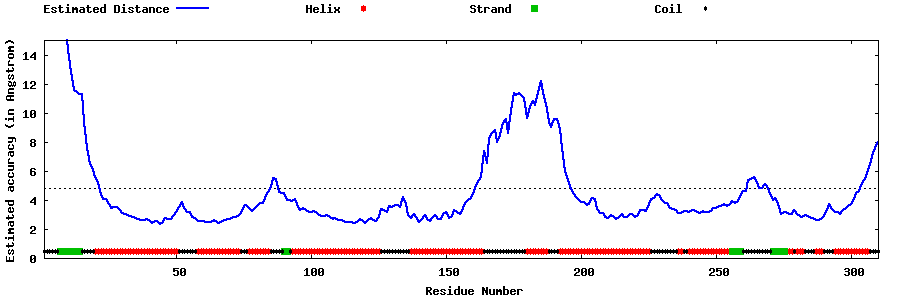 | |||
|
|
|||
 | |||
|
| |||
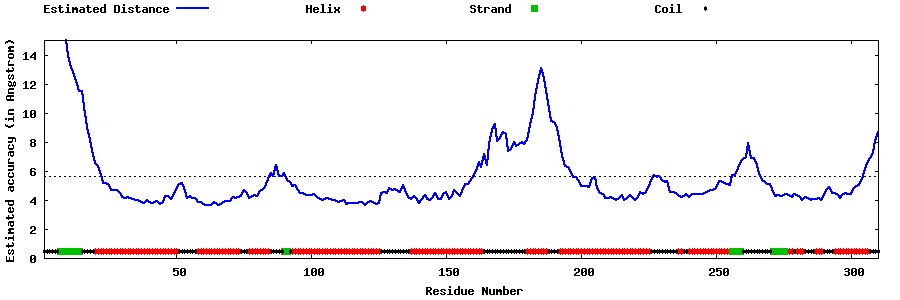 | |||
|
| |||
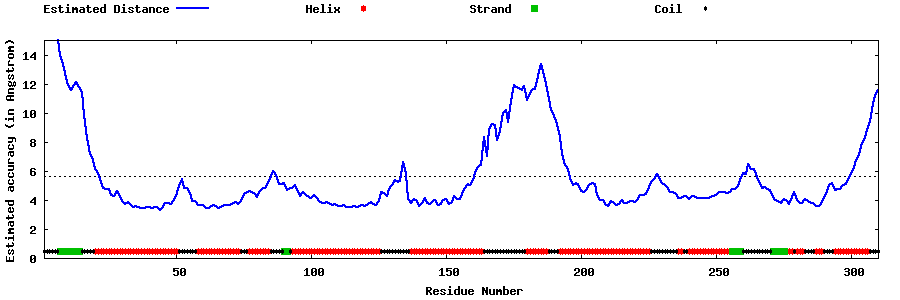 | |||
|
| |||
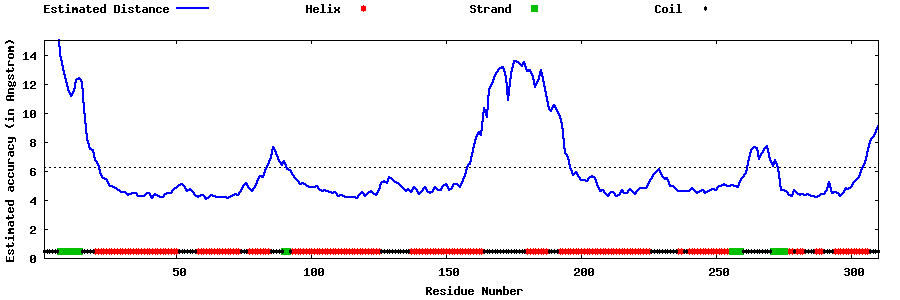 | |||
|
| |||
