GPCR-I-TASSER results for A6NM03
[Click on A6NM03_results.tar.bz2 to download the tarball file including all modeling results listed on this page]
| Submitted Sequence |
| >A6NM03 MELRNSTLGSGFILVGILNDSGSPELLYATFTILYMLALTSNGLLLLAITIEARLHMPMY LLLGQLSLMDLLFTSVVTPKALADFLRRENTISFGGCALQMFLALTMGSAEDLLLAFMAY DRYVAICHPLKYMTLMSPRVCWIMVATSWILASLIAIGHTMYTMHLPFCVSWEIRHLLCE IPPLLKLACADTSRYELIIYVTGVTFLLLPISAIVASYTLVLFTVLRMPSNEGRKKALVT CSSHLIVVGMFYGAATFMYVLPSSFHSPKQDNIISVFYTIVTPALNPLIYSLRNKEVMRA LRRVLGKYILLAHSTL |
| Predicted Secondary Structure |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | MELRNSTLGSGFILVGILNDSGSPELLYATFTILYMLALTSNGLLLLAITIEARLHMPMYLLLGQLSLMDLLFTSVVTPKALADFLRRENTISFGGCALQMFLALTMGSAEDLLLAFMAYDRYVAICHPLKYMTLMSPRVCWIMVATSWILASLIAIGHTMYTMHLPFCVSWEIRHLLCEIPPLLKLACADTSRYELIIYVTGVTFLLLPISAIVASYTLVLFTVLRMPSNEGRKKALVTCSSHLIVVGMFYGAATFMYVLPSSFHSPKQDNIISVFYTIVTPALNPLIYSLRNKEVMRALRRVLGKYILLAHSTL | |
| CCCCCCCCCSSSSSSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHHHHHHHCHHHHHHHHCCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCCCCCHHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCHHCCHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCCSSSSSCHHHHHHHCCCHHHCCCCHHHHHHHHHHHHHCCCCCCCCC | |
| 9998874102457877999801589999999999999999899999999748874453999988899998877721689999985069947869999999999999999999999999865166406555688425886999999999999999999999999314889989588854586899999713740999999999999999989999999999999981387615476033165868998999985465157078999998778389840721544102354413639999999999853023325769 |
| Predicted Solvent Accessibility |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | MELRNSTLGSGFILVGILNDSGSPELLYATFTILYMLALTSNGLLLLAITIEARLHMPMYLLLGQLSLMDLLFTSVVTPKALADFLRRENTISFGGCALQMFLALTMGSAEDLLLAFMAYDRYVAICHPLKYMTLMSPRVCWIMVATSWILASLIAIGHTMYTMHLPFCVSWEIRHLLCEIPPLLKLACADTSRYELIIYVTGVTFLLLPISAIVASYTLVLFTVLRMPSNEGRKKALVTCSSHLIVVGMFYGAATFMYVLPSSFHSPKQDNIISVFYTIVTPALNPLIYSLRNKEVMRALRRVLGKYILLAHSTL | |
| 8656130200100000004326111000130233233133333200200100030000001102000010110100310200000116532010200200110013002300100010010000000200200020033000000120021003003100100000100362402000002210030001003310220133133313311310330222000000103245123100000000000000132001000010204324433100002103320330030000103201300220022220144644 | |
| Values range from 0 (buried residue) to 9 (highly exposed residue) | |
| Predicted normalized B-factor |

| Top 10 templates used by GPCR-I-TASSER |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCCCCSSSSSSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHHHHHHHCHHHHHHHHCCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCCCCCHHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCHHCCHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCCSSSSSCHHHHHHHCCCHHHCCCCHHHHHHHHHHHHHCCCCCCCCC MELRNSTLGSGFILVGILNDSGSPELLYATFTILYMLALTSNGLLLLAITIEARLHMPMYLLLGQLSLMDLLFTSVVTPKALADFLRRENTISFGGCALQMFLALTMGSAEDLLLAFMAYDRYVAICHPLKYMTLMSPRVCWIMVATSWILASLIAIGHTMYTMHLPFCVSWEIRHLLCEIPPLLKLACADTSRYELIIYVTGVTFLLLPISAIVASYTLVLFTVLRMPSNEGRKKALVTCSSHLIVVGMFYGAATFMYVLPSSFHSPKQDNIISVFYTIVTPALNPLIYSLRNKEVMRALRRVLGKYILLAHSTL | |||||||||||||||||||||||||
| 1 | 3v2yA | 0.22 | 0.27 | 0.84 | 2.16 | Download | ------------------DKENSIKLTSVVFILICCFIILENIFVLLTIWKTKKFHRPMYYFIGNLALSDLLAGVAYTANLLLSGATTYK-LTPAQWFLREGSMFVALSASVFSLLAIAIERYITMLKN--------NFRLFLLISACWVISLILGG--------LPIMGWNCISA--------LSSCSTVLPLYHKHYILFCTTVFTLLLLSIVILYCRIYSLVRTRNSRSSEVALLKTVIIVLSVFIACWAPLFILLLLDVGCKVKTCDILFRLVLAVLNSGTNPIIYTLTNKEMRRAFIRIMGR--------- | |||||||||||||||||||
| 2 | 4iaqA | 0.18 | 0.21 | 0.84 | 2.37 | Download | ------------YIYQDSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISL---------PPCVVNTDH-----------------ILYTVYSTVGAFY---FPTLLLIALYGRIYVEARSRIILLMAARERKATKTLGIILGAFIVCWLPFFIISLVMPIHLAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK-------- | |||||||||||||||||||
| 3 | 3emlA | 0.18 | 0.21 | 0.88 | 3.75 | Download | --------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITISTG--FCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINC-FTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ---- | |||||||||||||||||||
| 4 | 2rh1A | 0.19 | 0.21 | 0.88 | 2.54 | Download | -------------------DEVWVVGMGIVMSLIVLAIVFGNVLVITAIAKFERLQTVTNYFITSLACADLVMGLAVVPFGAAHILMKMWTFGNFWCEFWTSIDVLCVTASIETLCVIAVDRYFAITSPFKYQSLLTKNKARVIILMVWIVSGLTSFLPIQMHWYRA----THQEAINCYAEET----CCDFFTNQAYAIASSIVSFYVPLVIMVFVYSRVFQEAKRQLNKLKEHKALKTLGIIMGTFTLCWLPFFIVNIVHVIQLIRKEVYILLNWIGYVNSGFNPLIYC-RSPDFRIAFQELLCL--------- | |||||||||||||||||||
| 5 | 4bvnA | 0.20 | 0.23 | 0.86 | 2.05 | Download | -------------------SQQWEAGMSLLMALVVLLIVAGNVLVIAAIGSTQRLQTLTNLFITSLACADLVVGLLVVPFGATLVVRGTWLWGSFLCELWTSLDVLCVTASVETLCVIAIDRYLAITSPFRYQSLMTRARAKVIICTVWAISALVSFLPIMM----HWWRDEDPQALKCYQD----PGCCDFVTNRAYAIASSIISFYIPLLIMIFVALRVYREAKE-----REHKALKTLGIIMGVFTLCWLPFFLVNIVNVFNLVPKWLFVAFNWLGYANSAMNPIILC-RSPDFRKAFKRLLA---------- | |||||||||||||||||||
| 6 | 3emlA | 0.18 | 0.21 | 0.88 | 4.13 | Download | ---------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAIT--ISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCF-TFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ---- | |||||||||||||||||||
| 7 | 4bvnA | 0.20 | 0.23 | 0.88 | 2.93 | Download | ------------------LSQQWEAGMSLLMALVVLLIVAGNVLVIAAIGSTQRLQTLTNLFITSLACADLVVGLLVVPFGATLVVRGTWLWGSFLCELWTSLDVLCVTASVETLCVIAIDRYLAITSPFRYQSLMTRARAKVIICTVWAISALVSFLPIMMHWWR----DEDPQALKCYQDP----GCCDFVTNRAYAIASSIISFYIPLLIMIFVALRVYREAKEQI--MREHKALKTLGIIMGVFTLCWLPFFLVNIVNVRDLVPKWLFVAFNWLGYANSAMNPIILC-RSPDFRKAFKRLLA---------- | |||||||||||||||||||
| 8 | 2z73A | 0.17 | 0.21 | 0.94 | 2.70 | Download | -EWYNPSIVVHPHWREFDQVPAVYYSLGIFIGICGIIGCGGNGIVIYLFTKTKSLQTPANMFIINLAFSDFTFSLVNGPLMTISCFLKKWIFGFAACKVYGFIGGIFGFMSIMTMAMISIDRYNVIGRPMAASKKMSHRRAFIMIIFVWLWSVLWAI---GPIFGWVLCNDYI----------------SRDSTTRSNILCMFILGFFGPILIIFFCYFNIVMAQAGANAEMRLAKISIVIVSQFLLSWSPYAVVALLAQFGPLEWVTPYAAQLPVMFAKASAIHNPMIYSVSHPKFREAISQTFPWVLTCCQFDD | |||||||||||||||||||
| 9 | 3emlA | 0.18 | 0.21 | 0.88 | 5.32 | Download | --------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS--TGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAII-VGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ---- | |||||||||||||||||||
| 10 | 3emlA | 0.18 | 0.21 | 0.88 | 5.53 | Download | IMG--------------------SSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAIT--ISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFEDVVPMNYMVYFNFFACVLV-----------PLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWL-PLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ---- | |||||||||||||||||||
| ||||||||||||||||||||||||||
| Top 5 Models predicted by GPCR-I-TASSER |
| Generated 3D models | Estimated local accuracy of models | ||
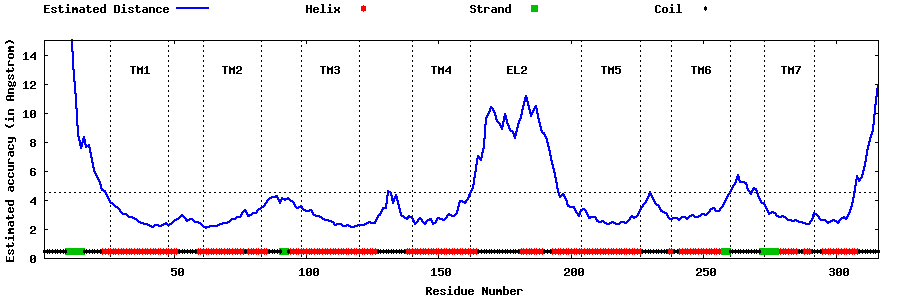 | |||
|
|
|||
 | |||
|
| |||
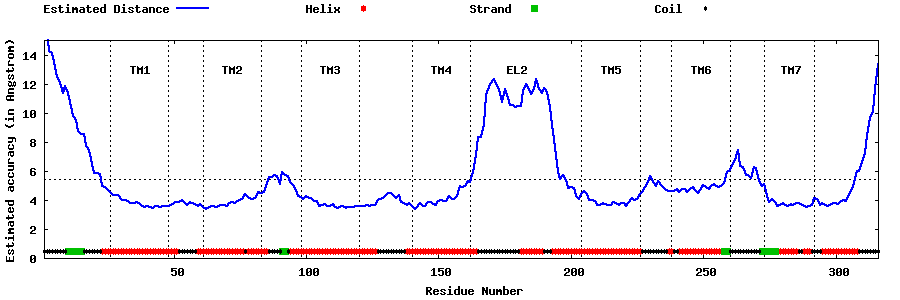 | |||
|
| |||
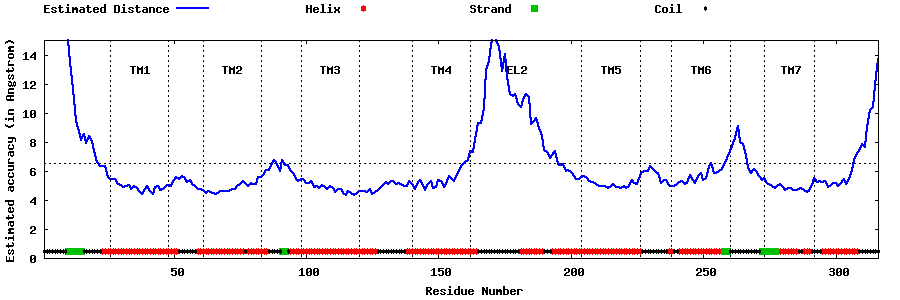 | |||
|
| |||
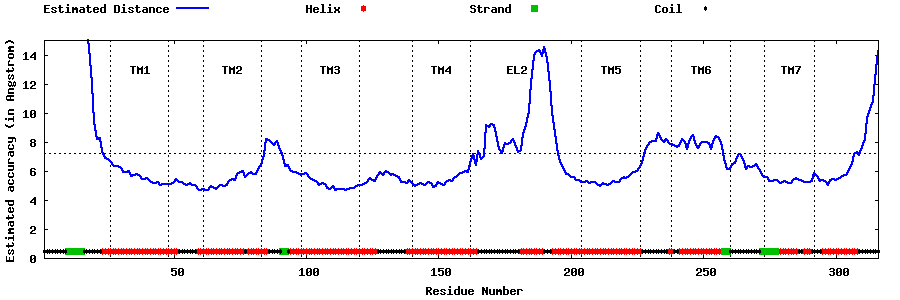 | |||
|
| |||
| Please cite following articles when you use the GPCR-I-TASSER server: | |
| J Zhang, J Yang, R Jang, Y Zhang. Hybrid structure modeling of G protein-coupled receptors in the human genome, submitted (2015). |